Athena란?
Amazon S3에 저장된 데이터를 대상으로 SQL 쿼리를 실행할 수 있는 서비스이다. 몇 초만에 대용량의 데이터를 조회해 결과를 얻을 수 있다.
이 글에서는 ALB의 Access log를 수집해 Athena를 이용해 분석해 볼 것이다.
사용 방법
1. 로그를 저장할 버킷 생성

2. 버킷 정책 설정
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::600734575887:root"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::logbucket3333/*"
}
]
}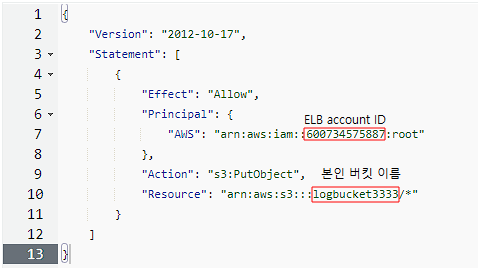

ELB가 위치한 지역의 ID값을 적으면 된다
3. ALB Access log 활성화
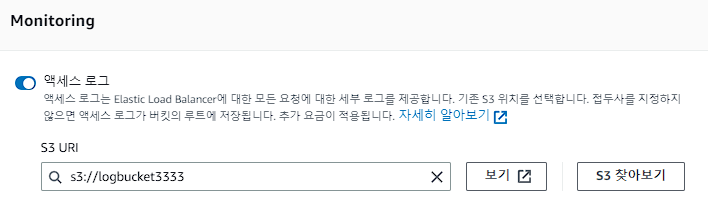
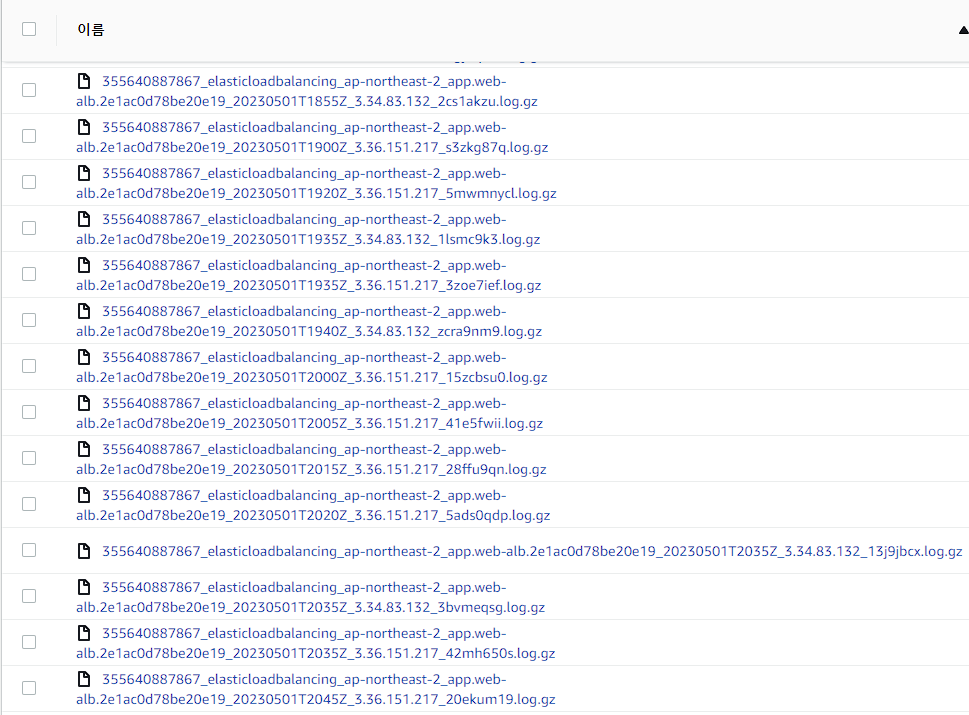
몇분 기다린 후에 확인해 보니 로그가 수집이 됐다

4. Athena로 로그 분석
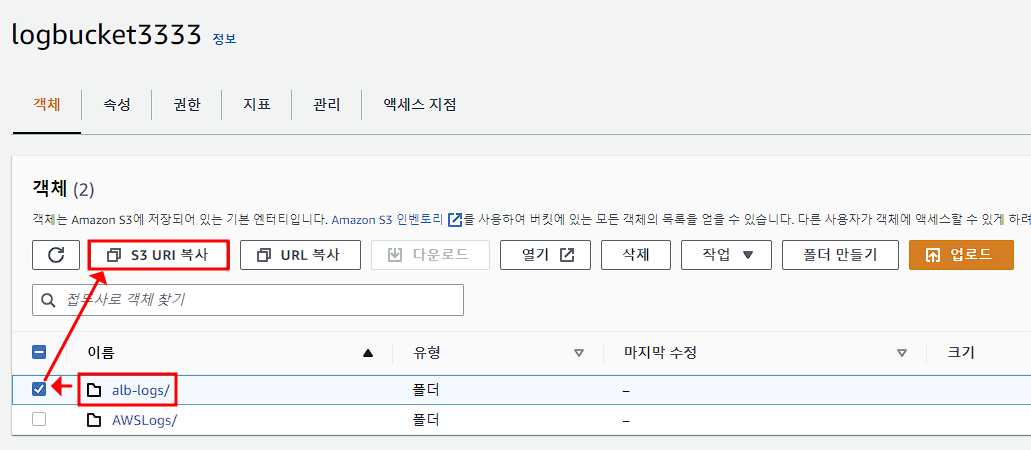
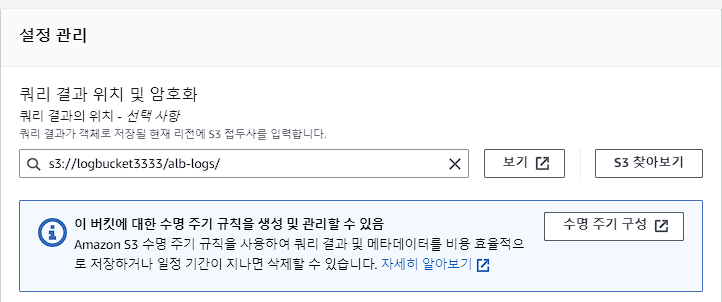
쿼리 편집기에서 데이터베이스 생성. sql기반이므로 sql문법을 알면 더 익숙할 것이다.
데이터베이스 생성
create database alb_log_database;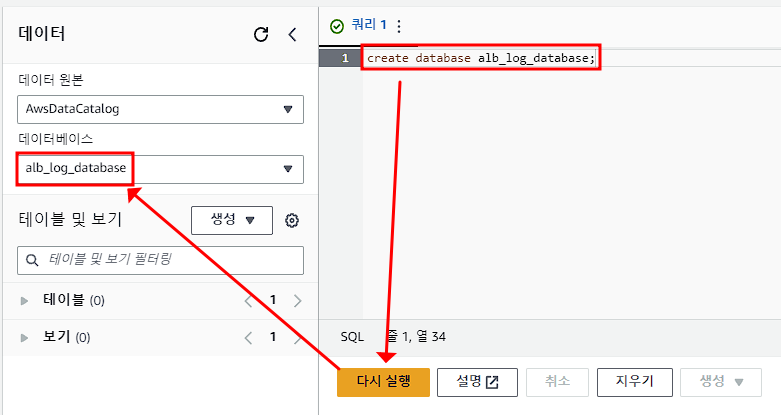
alb로그의 테이블 생성
CREATE EXTERNAL TABLE IF NOT EXISTS alb_log_table (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
PARTITIONED BY
(
day STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://logbucket3333/AWSLogs/355640887867/elasticloadbalancing/ap-northeast-2/'
TBLPROPERTIES
(
"projection.enabled" = "true",
"projection.day.type" = "date",
"projection.day.range" = "2023/05/01,NOW",
"projection.day.format" = "yyyy/MM/dd",
"projection.day.interval" = "1",
"projection.day.interval.unit" = "DAYS",
"storage.location.template" = "s3://logbucket3333/AWSLogs/355640887867/elasticloadbalancing/ap-northeast-2/${day}"
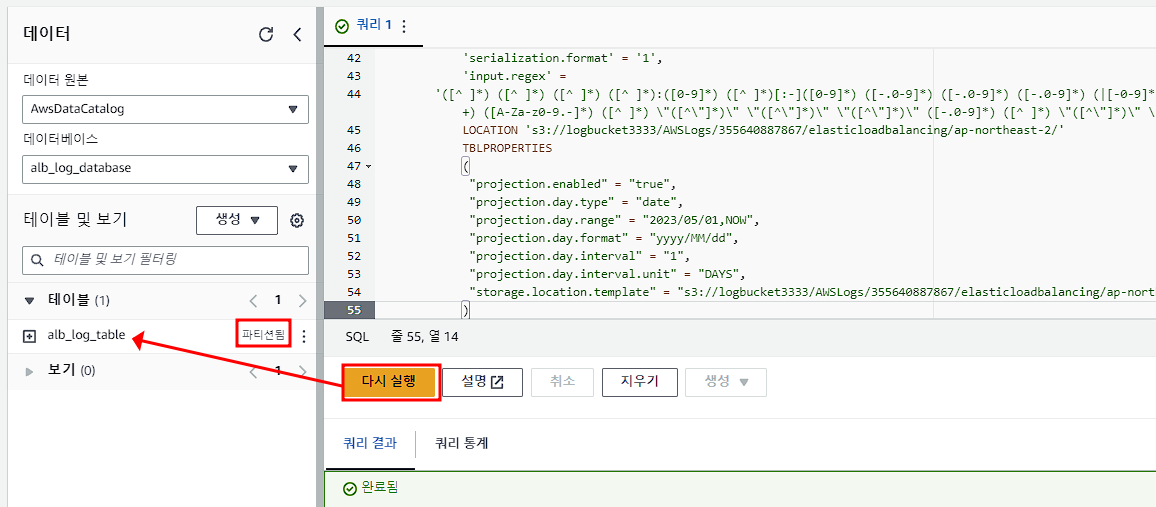
)이 코드에는 파티셔닝 적용이 되어있다.
아래에서 11번째 줄과 가장 아래줄인 s3://버킷 부분을 본인의 버킷에 생긴 로그 경로에서 날짜 적힌 폴더의 상위폴더까지만 URI경로를 복사해서 붙여 넣기 하면 된다. 6번째 줄에 day.range부분에도 현재 날짜를 입력하면 된다.
파티셔닝이란?
데이터를 분할저장하여 대용량의 데이터를 작은 덩어리로 나누는 것을 말한다. 이렇게 나눈 데이터를 파티션이라고 하며, 파티셔닝을 통해 데이터 검색시간을 줄일 수 있다. 원래라면 모든 로그가 조회되기 때문에 로그가 많아지면 쿼리를 수행할 때 시간이 굉장히 오래 걸리는 반면 위에 있는 코드인 특정 연도, 월, 일별로 파티셔닝을 하면 쿼리를 수행할 때 전체 데이터를 검색하는 것이 아니라 해당 파티션(특정날짜)만 검색할 수 있다. 이를 통해 검색시간이 크게 단축된다.
전체 데이터를 조회해 보자
select * from alb_log_table;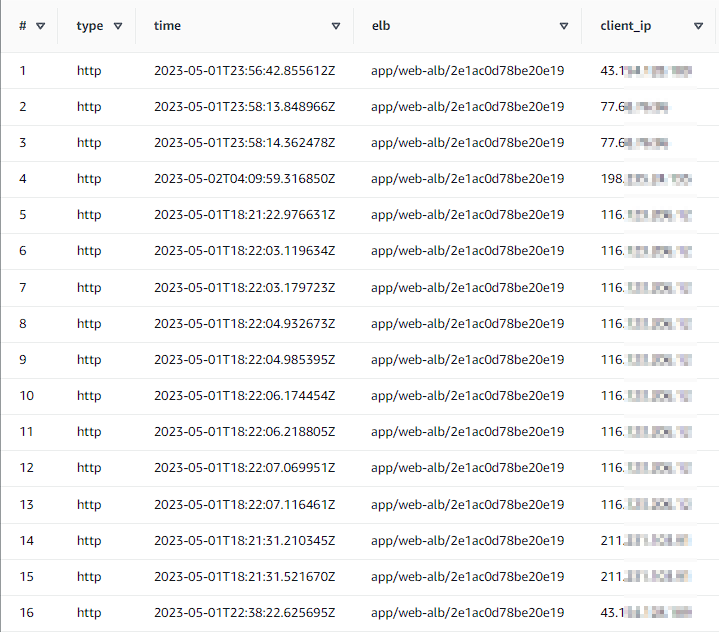

데이터 파티셔닝을 사용해서 중요한 열 몇 개만 가져와보자
select client_ip, user_agent, day from alb_log_table where day='2023/05/01';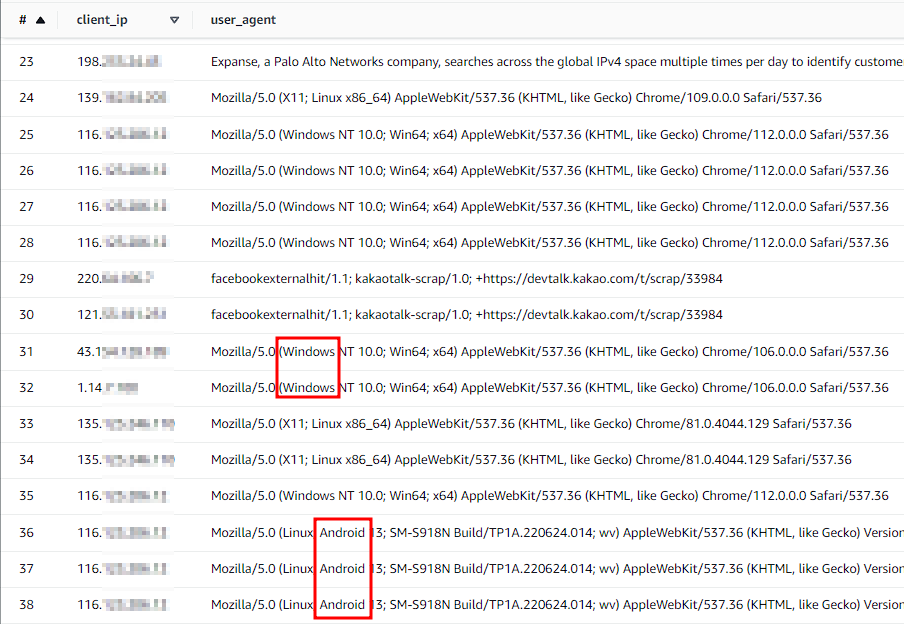


.gz파일을 직접 다운받아서 메모장에서 보게 된다면 굉장히 복잡하고 로그를 분석하기도 힘들다. 이럴 때 Athena를 이용하면 sql문을 사용해서 원하는 정보만 빠르고 간편한 방법으로 로그를 분석할 수 있다.
'AWS > Service' 카테고리의 다른 글
| [AWS] EBS (0) | 2024.04.24 |
|---|---|
| [AWS] VPN (with GCP) (0) | 2023.05.03 |
| [AWS] AWS Backup (0) | 2023.04.30 |
| [AWS] SNS (0) | 2023.04.29 |
| [AWS] WAF (0) | 2023.04.29 |